ATLASS - Pilot project
Short description
A small-scale pilot project running within the research project "ATLASS - Automated Transcription and Linkage of Archival School Data from Sweden". The aim of the ATLASS project is to apply advances in machine learning and record linkage techniques to the detailed and structured information available in Swedish archives to build a unique research infrastructure with individual-level data on historical school records from the first half of the 20th century.
Since summer 2021 a small-scale pilot project is running with a number of selected archives. The aims of the pilot are to develop methods for all the distinct steps in the Atlass project, including:
- Software development
- Collection of sources
- Generation of training data
- Segmentation
- Transcription
- Record linkage
The pages below show the current status of these various steps.
Software Development
An online tool has been developed, which integrates all the essential steps in the data collection and transcription steps, including:
- Upload function for archives
- Extraction of images from scans
- Generation of Training data for 15 different content types
- Extraction of image snippets
- Export of manually transcribed snippets
The image below shows how the upload function for archives works.
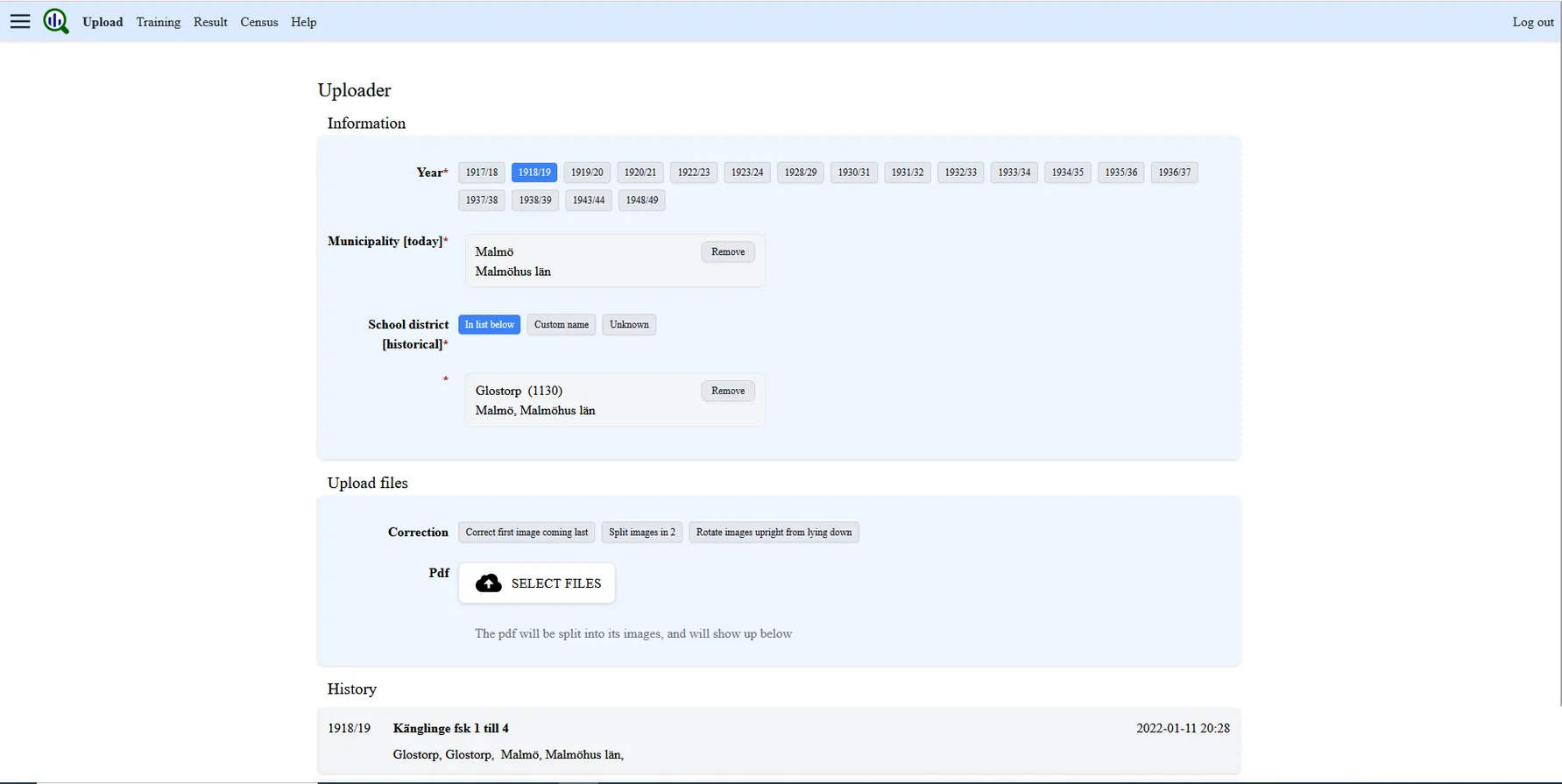
Collection of Sources
So far, 1262 DmE's have been uploaded, including a total of 16852 pages.
Generation of Training Data
We have developed an online tool tailor-made for the manual transcription of records the DmE. It allows users to generate training data within pre-defined classes, which can be flexibly adapted to the information contents of different cells (i.e. names, birth dates, school grades, parental professions, etc). For all string fields, historical censuses have been used to make the software come up with suggestions for the transcribers. The software also converts information on the layout of the form; which is essential given that there was slight variation in layout over time.
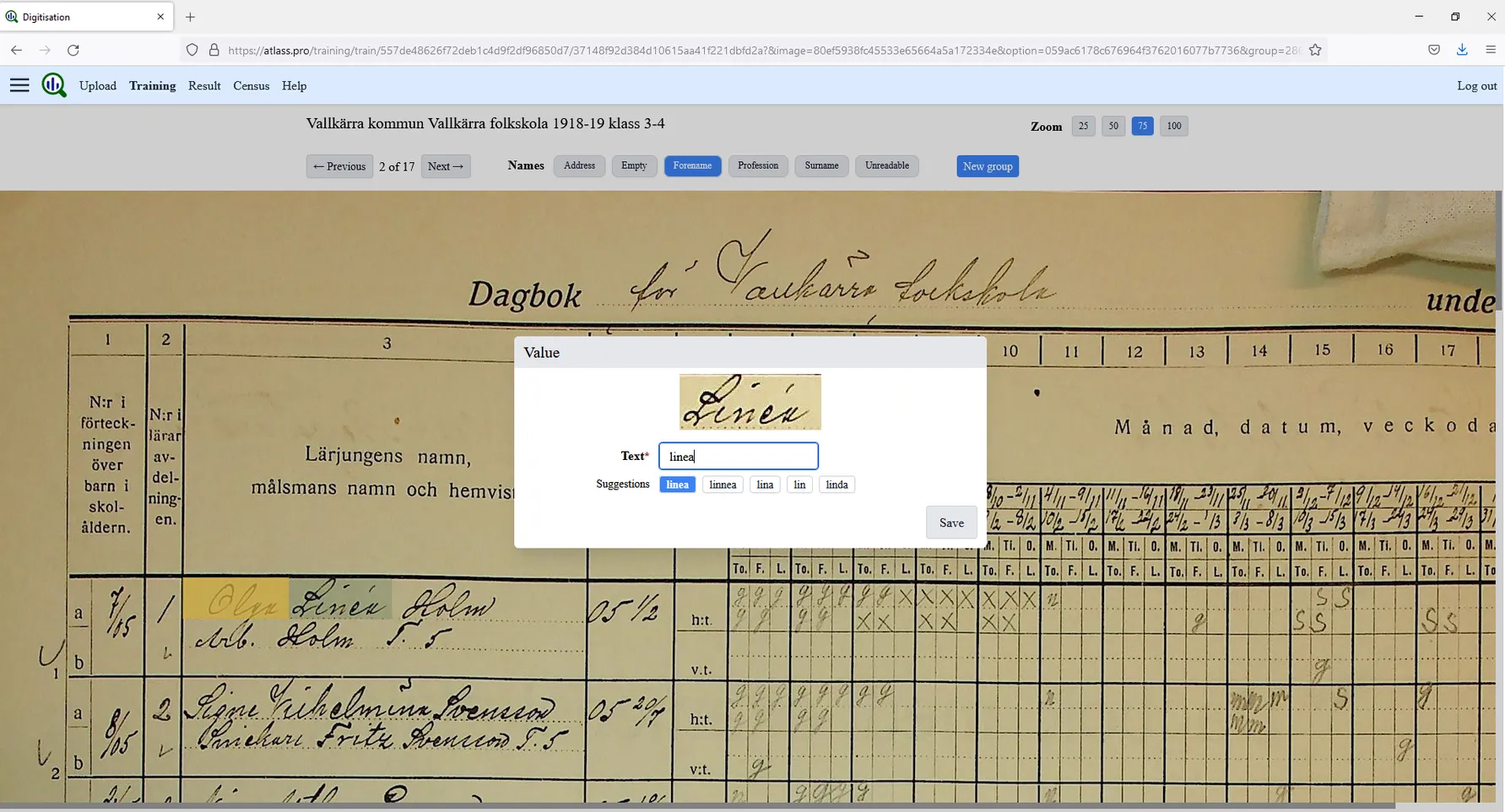
In total, 165705 items of training data have been generated to date.
Segmentation
This step involves finding the exact position of the tables in each document, and extraction of all fields within these tables. This part of the process is based on computer vision and semantic segmentation convolutional neural network architectures, like Tableparser which -- after training -- identifies all horizontal and vertical lines and/or columns in the document. The resulting snippets are saved for processing in the next step.
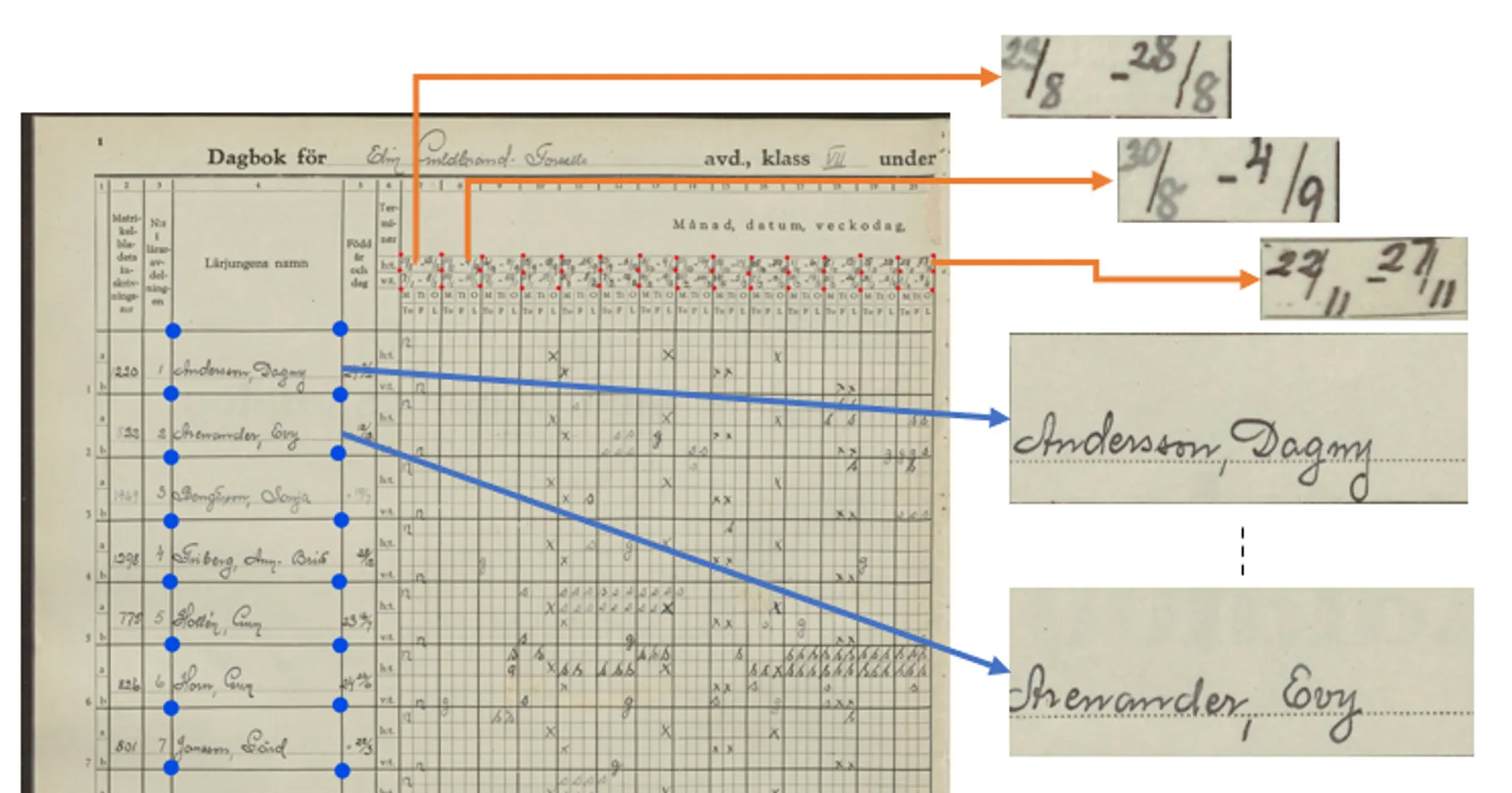
Transcription
The final step of the digitisation is transcription of the image snippets. This step in the process is based on Convolutional Neural Network (CNN) and Visual Transformers (ViT) architectures-- and generates two outcomes: a transcription of the text or numbers in the field, and a measure of the confidence of the transcription. The latter is a measure of how confident the networks are, that the information content has been transcribed correctly. The CNN and ViT architectures have recently successfully been applied to transcription of handwritten Danish names as well as handwritten surnames from the 1930 UC census with character error rates below 2 percent, see e.g. Dahl et al (2021).
During the pilot, all 1910 birthbooks -- a source available on the website of the National Archives -- have been transcribed; including all 134,000 births in that year (some of which are recorded twice since hospitals kept their own birthbooks). The below figure gives an example of the outcome of the transcription.
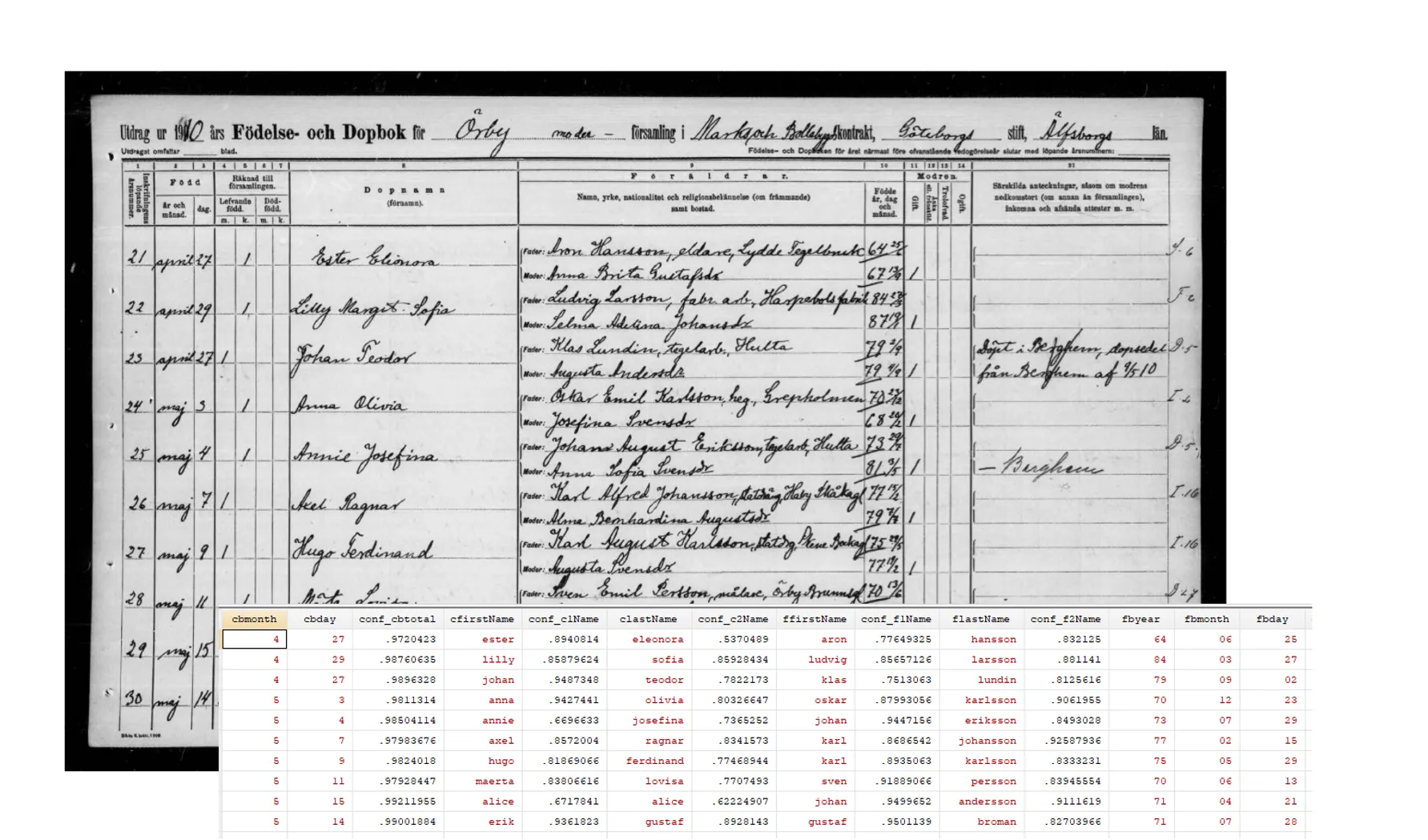
Record Linkage
During the pilot phase, record linkage algorithms for two datasets have been developed and tested. Both algorithms conduct probabilistic linkage based on the EM algorithm (cf. Abramitzky et al, 2020). The record linkage procedures were implemented in several different rounds, altering in each step the set of variables for which an exact match is required. Preliminary analyses show that very high overall match rates can be achieved, without having to accept a large proportion of false positive links (see below).
Exam Catalogues (DmE)
An algorithm was developed for the record linkage between DmE and data from the Swedish Death Index and the 1950 census. In combination, these two dataset cover virtually the entire Swedish population in the relevant period. Variables common to both these datasets and DmE are birth dates, forenames and surnames. In addition, all three datasets include information on parish of residence, though at different points in time. We therefore estimated the probability of moving certain distances from a dataset containing exact information, and used this geographic information in probabilistic record linkage.
The record linkage was carried out in five rounds. The first round, which was the most stringent in terms of variables requiring an exact match, achieved a match rate of 75.6 per cent. This was achieved by setting a cutoff for the estimated probability of a correct match at 0.62.
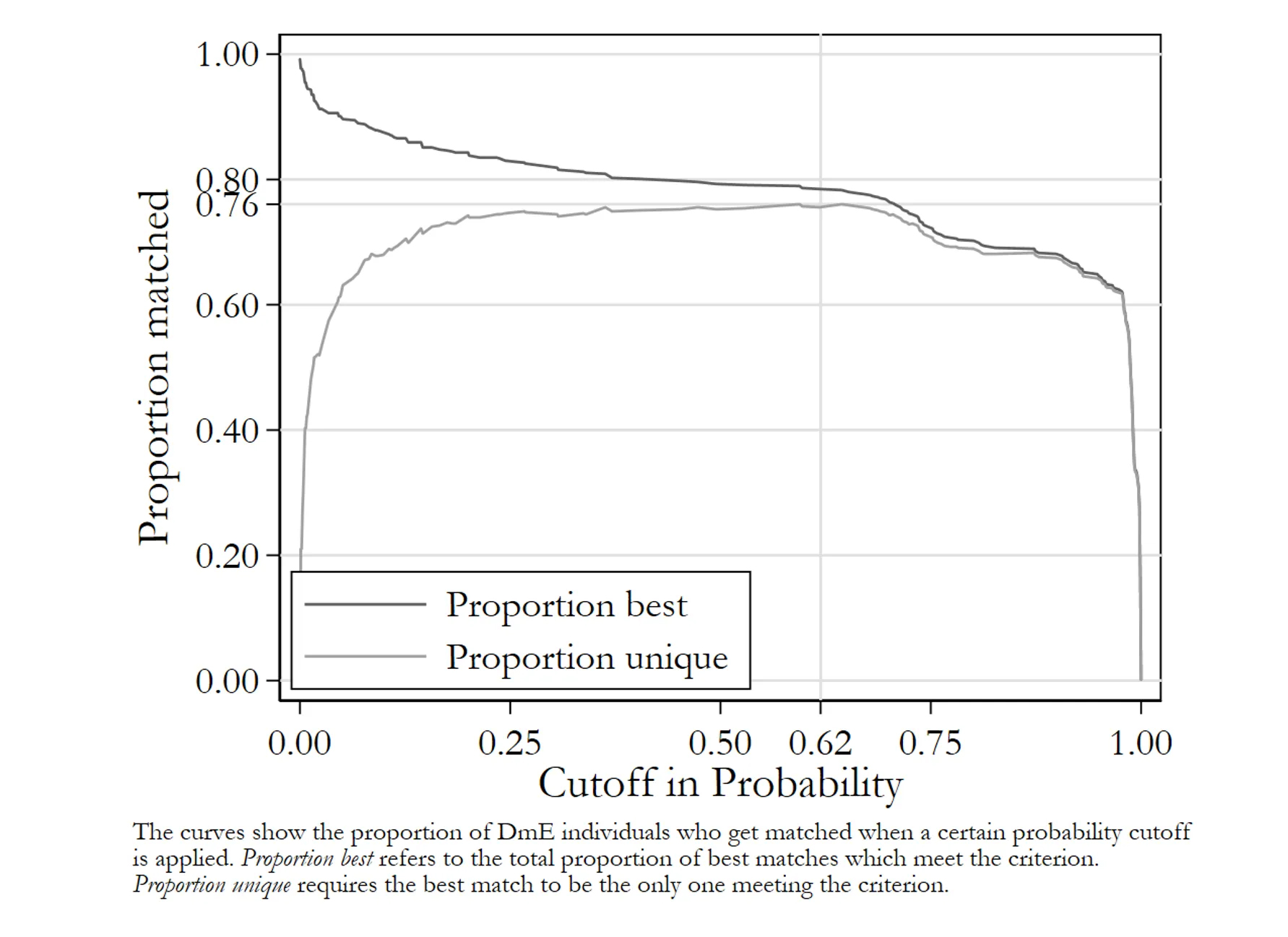
By subsequently allowing the year, month, and day of birth being transcribed with error, the total match rate could be increased even further. The overall match rate over five rounds was 90.8 per cent. This is much higher than what is normally reported in other studies, which typically rely on American data. It raises the question whether the higher match rates are achieved at the cost of high false positive rates. In order to investigate this, we conducted record linkage leaving surnames out. The data are still detailed enough so as to enable high match rates without them. Based on average surname similarity for any linked sample, the false positive rates could thus be estimated. This is done in the following figure.

When surnames are disregarded as linkage variables, a match rate of 70 per cent could be achieved by setting the cutoff at 0.53. However, regardless of the threshold chosen, the surname similarity was never below 0.88 in the matched sample (the best possible score for identical names is 1). Conversely, the estimated false positive rate was never above 8.9 per cent, and at the 0.53 cutoff maximising the number of links, it was as low as 2.6 per cent. This is very low in comparison with most other applications.
1910 Birthbooks
The universe of birthbooks from 1910 have been transcribed (see above). Linkage was done separately for children, mothers, and fathers; and for each of these three categories, the algorithm was carried out in five distinct rounds, with different stringency of the linkage criteria. The cumulative match rates were 88.5 per cent for children, 72.6 per cent for mothers and 64.5 per cent for fathers. False positive rates were estimated for parents based on married couples who were also present in the 1950 census; the estimated rate was between 2 and 3 per cent in each run of the algorithm.
Next to high match rates and low false positive rates, representativeness is an importance performance indicator for a linkage algorithm. The question is whether the linked dataset is representative of the target population, which in this case is the children, mothers and fathers of 1910 births. The table below give an overview of how the linked sample compares to the families of 1910 births in the 1910 census. We make two comparisons: one for the sample of linked children, and one for children for which at least one parent was linked as well.
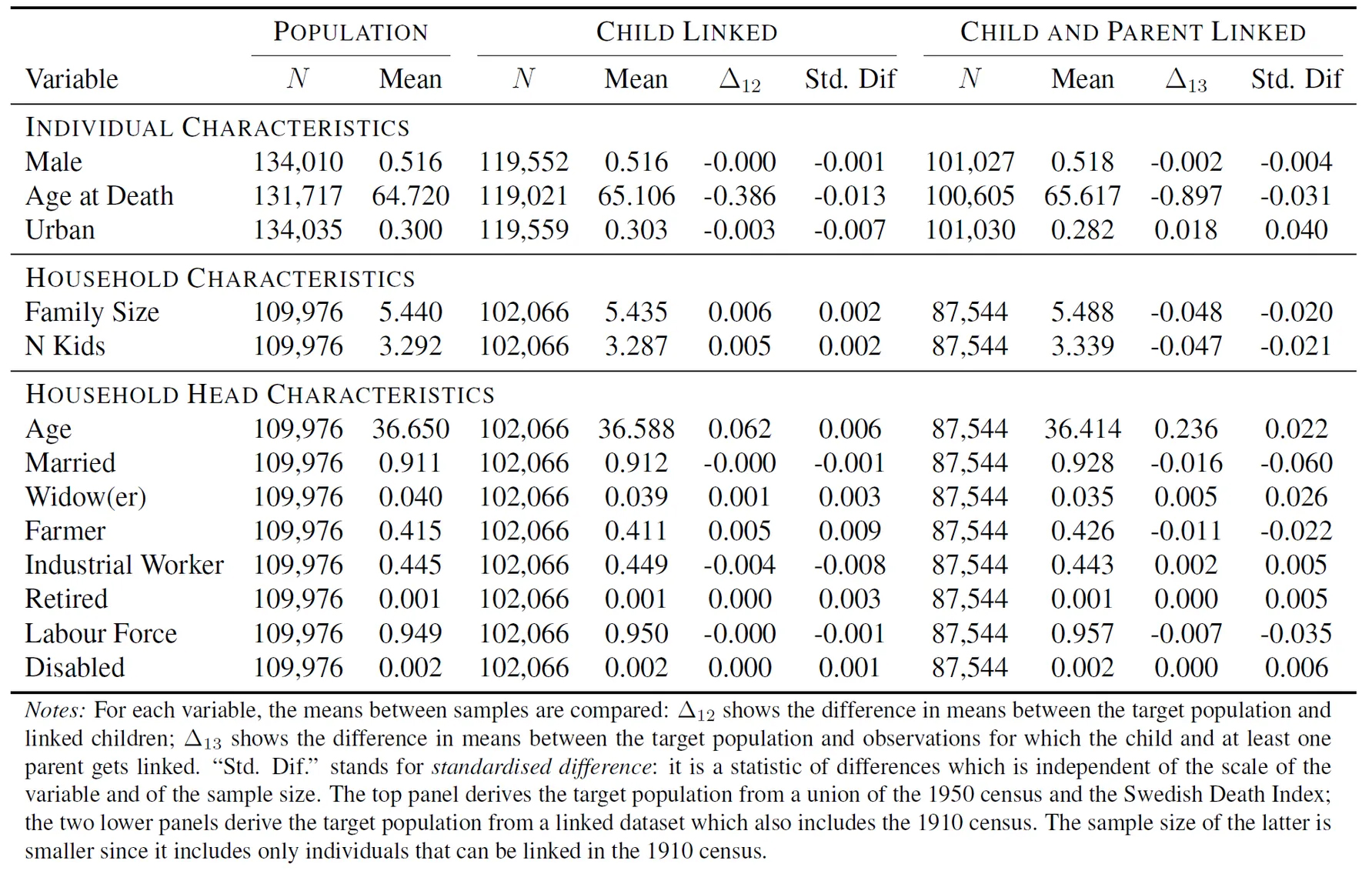
The linked sample appears to be highly representative according to most variables. The variable exhibiting the largest discrepancy is marital status of the parents: it is 1.6 percentage points larger in the sample of linked families. This is probably related to the fact that the chances of matching at least one parent are larger when the parents are married.
